Parquet 공식문서를 기반으로 내부구조에 대해서 깊게 이해하고자 정리합니다.
공식문서 첫 부분인 Overview, Motivation 부터 이해가 쉽지 않았기 때문에 이해한 내용의 흐름에 따라 작성하였습니다.
Parquet 정의
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides high performance compression and encoding schemes to handle complex data in bulk and is supported in many programming languages and analytics tools.
- 파케이는 Columnar 형식의 파일 포맷
- 대용량 데이터 처리하기 위한 압축 및 인코딩을 제공
- 바이너리 포맷
실제 파케이 파일은 아래 형태로 저장됩니다.
00000010 15 02 15 02 1c 15 02 15 00 15 02 15 |................|
00000020 02 15 04 15 00 15 02 15 02 15 04 15 |................|
00000030 00 15 02 15 02 15 04 15 00 15 02 15 |................|
000001f0 1c 15 00 15 02 15 02 15 00 15 02 15 |................|
00000200 1c 15 00 15 02 15 02 15 00 15 02 15 |................|
00000210 28 0c 15 02 15 00 15 02 15 02 15 04 |(...............|
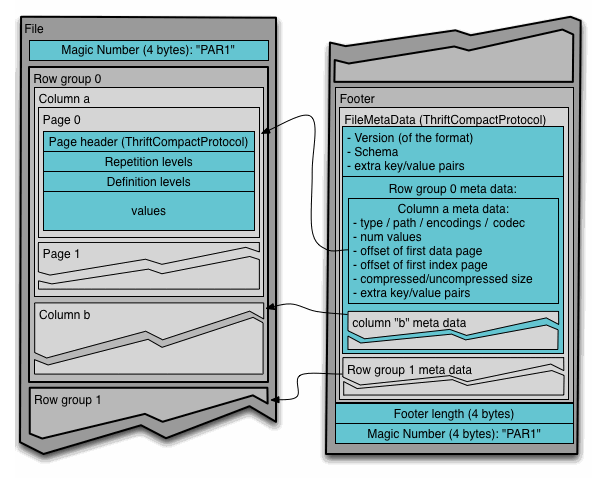
파일 구조
파케이 파일의 전체 구조는 아래와 같습니다.
4-byte magic number "PAR1" # 파일 식별자
<Column 1 Chunk 1> # Row Group
<Column 2 Chunk 1>
...
<Column N Chunk 1>
<Column 1 Chunk 2>
<Column 2 Chunk 2>
...
<Column N Chunk 2>
...
<Column 1 Chunk M>
<Column 2 Chunk M>
...
<Column N Chunk M> # Row Group
File Metadata # Footer(스키마 + 통계)
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1" # 파일 식별자
이러한 형식이기 때문에 리더는 파일의 마지막 8 바이트만 읽어서 메타데이터에 접근할 수 있습니다.
파일을 역순으로 보면,
- 4 바이트의 파일 식별자
- 4 바이트의 푸터 길이 식별
- 푸터 길이 만큼 푸터 읽기
물리적 스토리지 레이아웃 모델
처음 파케이의 파일구조를 보고는 이해하기 어려웠습니다.
개인적으로 물리적 스토리지 레이아웃에 대한 영상을 먼저 공부한 후에 이해하기가 훨씬 수월했습니다.
물리적 스토리지 레이아웃에 대해서 먼저 정리합니다.
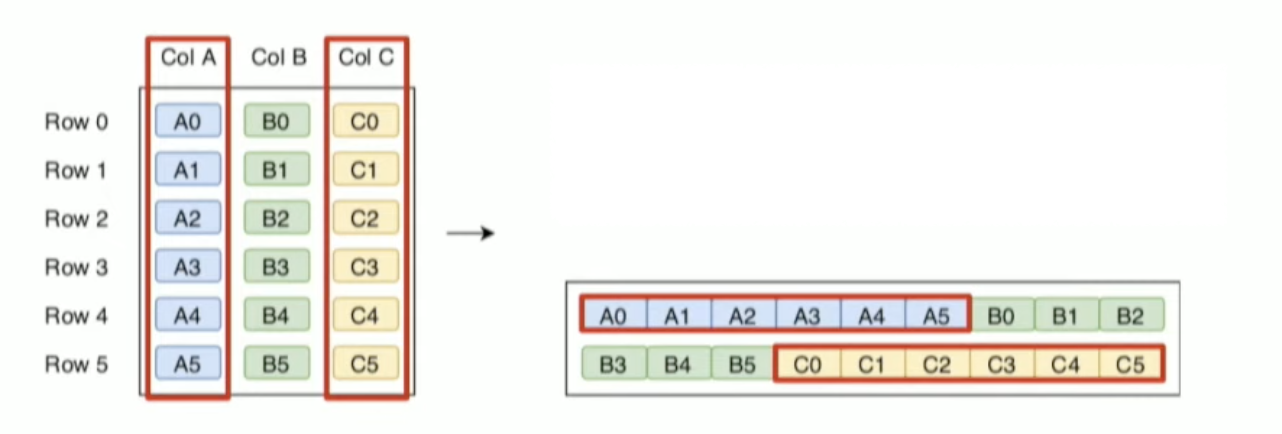
하나의 데이터 프레임에 대해서 3가지 모델의 형태로 저장할 수 있습니다.
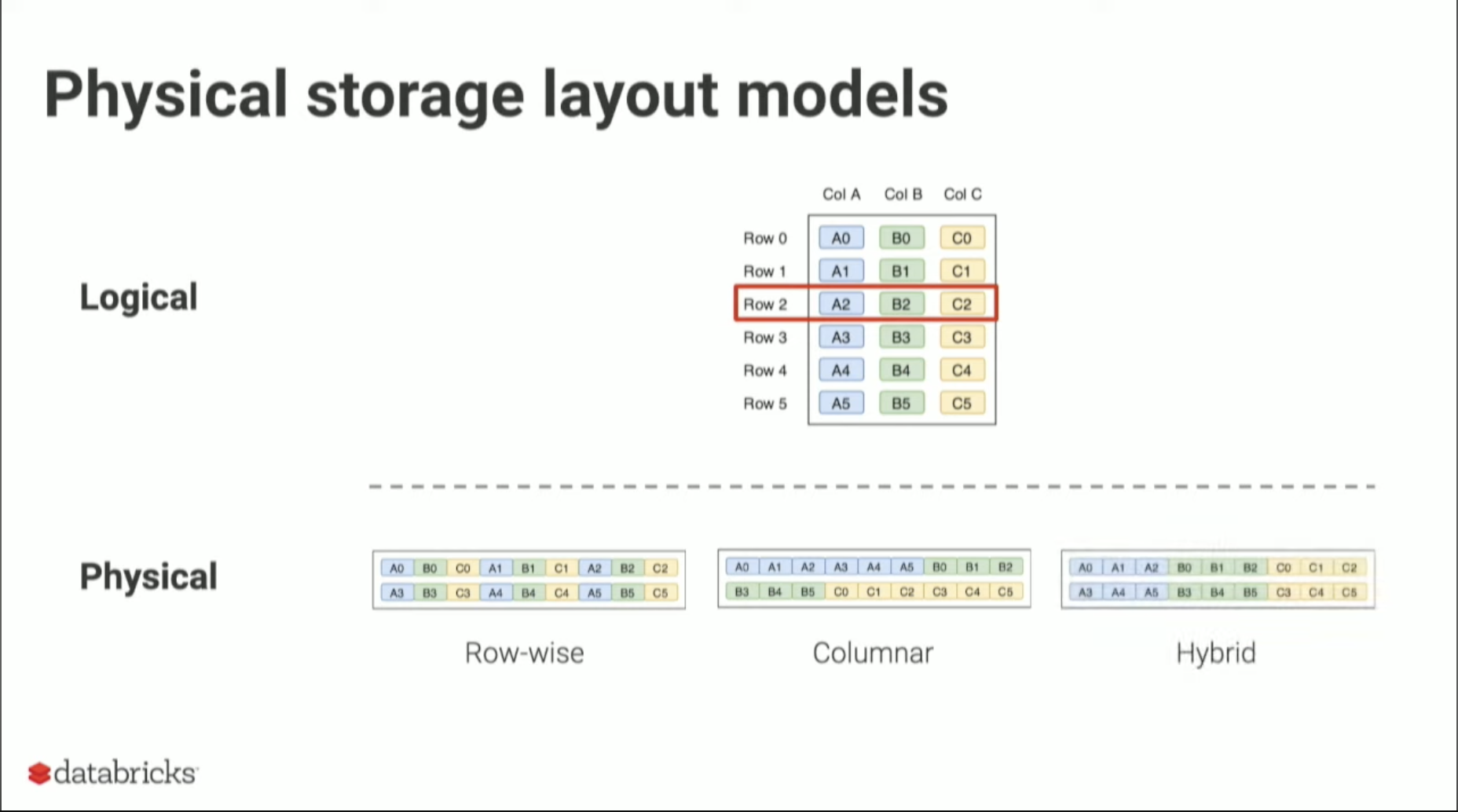
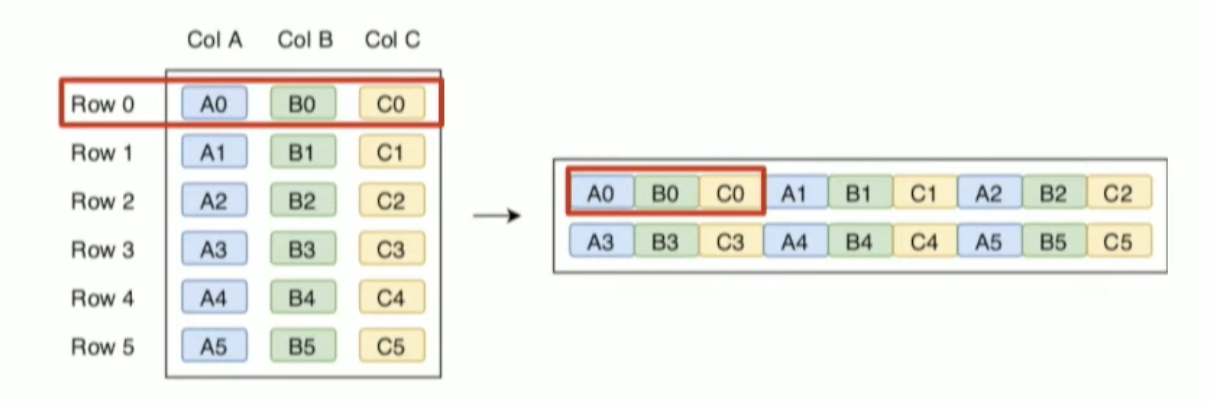
row-wise 모델은 다음과 같습니다.
row를 순차적으로 저장하며 가장 기본적인 모델입니다. 이 모델은 데이터를 수평분할(Horizontal Partitioning) 합니다.
row-wise 모델이 왜 항상 효율적인 저장 모델이 아닌지 상황에 따라 다른지에 대해서 이해해 보겠습니다.
일반적으로 OLTP 와 OLAP의 전제는 다음과 같습니다.
- OLTP 는 전체 행을 포함하는 수많은 오퍼레이션을 가진 워크로드
- OLAP 는 특정 열만을 필요로 하는 few Large 오퍼레이션을 가진 워크로드
리더는 물리적 스토리지 레이아웃에 쓰인 방식으로 데이터를 읽게 됩니다.
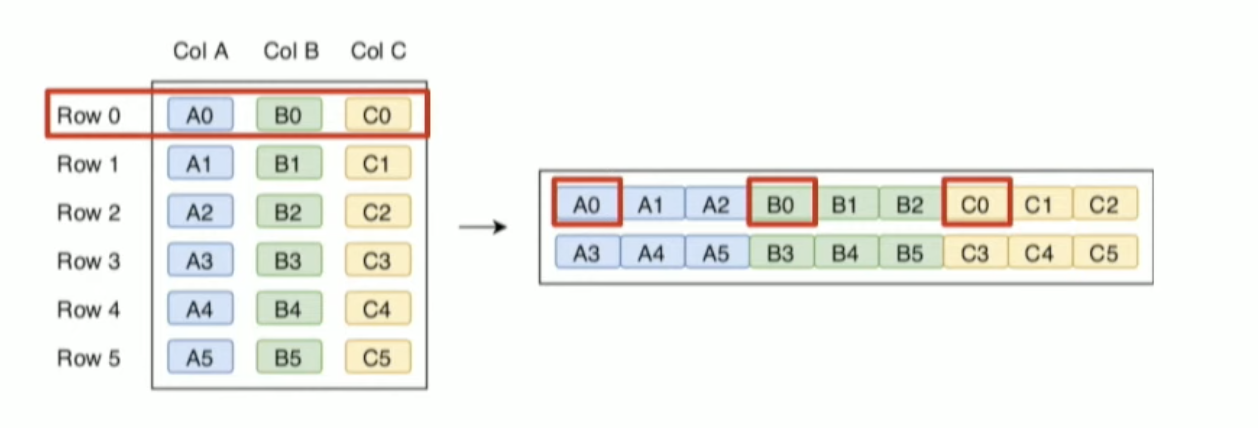
만약, OLTP 워크로드에서 연속된 레이아웃으로 저장된 a0,b0,c0 을 읽는다면 효율적으로 읽습니다.
반면, OLAP 워크로드에선 특정 열만을 읽습니다.
만약 Column B 를 제외하고 읽기를 한다면 파일 입출력에서 리소스를 낭비하게 됩니다.
데이터는 쓰인 데이터를 순차적으로 읽어서 A0, B0, C0 순서로 읽지만 필요 없는 B0을 제외할 테니까요.
이는 단편화된 메모리 접근입니다.
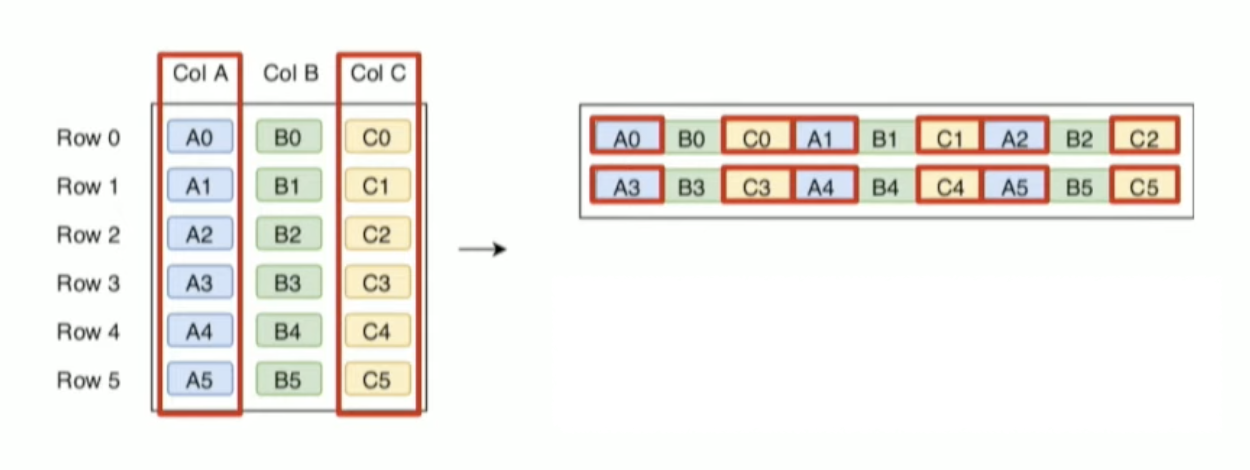
Columnar 모델에서는 이 상황에서 효과적으로 작동합니다.
Columnar 모델은 데이터를 수직분할(Vertical Partitioning) 하여 저장합니다.

row-wise 모델와 다르게 column pruning이 발생할 경우 저장된 데이터를 읽을 때 연속적으로 읽습니다.
상황에 따라서 효과적인 데이터 저장 방식이 있다는 것을 이해하였습니다. 다만 Columnar 방식의 데이터 방식은 왜 쓰는 것일까요?
Columnar 의 경우 아래 두 가지 특징이 있습니다.
- Free Projection Pushdown
- Compression Opportunity
Free Projection Pushdown의 경우 위 예시처럼 Column Pruning을 의미합니다.
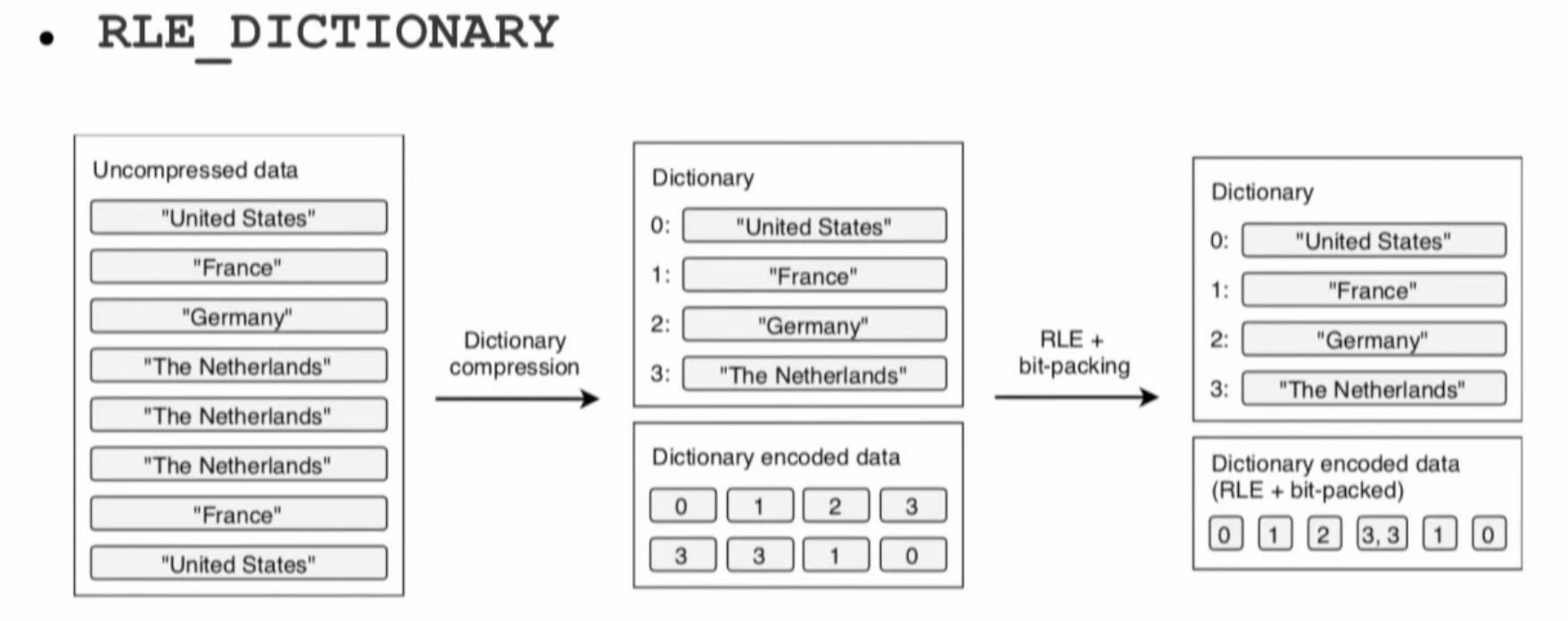
그렇다면 왜 압축 과정에서 기회가 발생할까요? 파케이 파일은 데이터를 인코딩 후에 압축합니다.
하나의 컬럼의 값들은 일반적으로 유사한 형태를 띠는 경우가 많습니다.
예를 들면 Column A 가 실제로는 Country 라는 컬럼이라고 가정하겠습니다.
해당 Country의 카디널티는 모든 경우를 가정하더라도 전세계의 국가 수로 고정될 것이고 이는 유한할 것입니다.
이런 경우 값에 인코딩을 한다면 유사한 값들이 다수 존재할 것입니다.
인코딩 방식 중 Run-Length Encoding은 같은 값이 연속될 때 유리합니다.
Columnar 방식일 경우 데이터의 연속성이 높아질 것이고 이러한 인코딩 방식이 사용되어 효과적인 압축 기회가 발생합니다.
그렇다면 실제 Parquet 과 ORC의 모델인 Hybrid에 대해서 알아보겠습니다.
Hybrid는 이 두 방식을 모두 사용합니다.
데이터를 Row 기준으로 수평분할한 후 해당 Row Group 안에서는 Columnar 처럼 수직분할하여 저장합니다.
하나의 Row Group은 지정된 block size에 맞춰 분할됩니다.
파일 구조 자세히 보기
위 물리적 스토리지 레이아웃 모델에 대한 이해를 바탕으로 Row Group, Column Chunk, Page에 대해서 자세히 알아보겠습니다.
Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
*Default : 128 MB
Row group : 데이터를 논리적으로 행으로 수평분할합니다. row group에 대해 물리적인 구조로 나뉘어졌다고 보장할 수 없습니다. row group은 dataset의 각 column에 대한 column chunk로 구성됩니다.
Column chunk: A chunk of the data for a particular column. They live in a particular row group and are guaranteed to be contiguous in the file.
Column chunk: 특정 column에 대한 청크입니다. 청크는 특정 row group에 있으며 파일에서 연속적으로 있다고 보장할 수 있습니다.
Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which are interleaved in a column chunk.
*Default : 1 MB
Page: Column chunk는 page로 나뉩니다. page는 압축 및 인코딩 측면에서 개념적으로 분할할 수 없는 단위입니다. 인터리브되는(interleaved) 컬럼 청크에 여러 페이지 타입이 있을 수 있습니다.
위 설명을 통해서 Row Group -> 여러 개의 Column Chunk -> 여러 개의 Page 라는 계층 구조임을 알 수 있습니다.
세부적으로 나눠서 보면 다음과 같습니다.
- 하나의 파케이 파일에는 여러 개의 Row Group이 존재하며 각 Row Group 마다 데이터의 통계를 갖고 있습니다.
- 하나의 Row Group은 컬럼의 수 만큼 Column Chunk를 가지고 있습니다. 컬럼 하나에 해당하는 데이터들의 묶음입니다.
Column A 에 순차적으로 a0,a1,a2,a3 라는 값이 존재한다면, Chunk A = [a0, a1, a2, a3] - Page는 데이터가 압축 및 인코딩 되는 형태(단위)입니다. Page가 구분되는 기준은 Page 사이즈 설정 옵션입니다.
Page1 = [a0, a1], Page2 = [a2, a3], page3 = [a4] 형태입니다.
파케이 설계 목적
위 내용들을 바탕으로 이제 파케이 설계 목적을 이해할 수 있습니다.
We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem.
** 왜 압축에 이점이 있는지 효율적인 columnar 데이터 방식이 무엇인지 **
Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented.
파케이의 궁극적 목적은 병렬화(parallelization) 라고 생각합니다.

- 병렬 처리 프레임워크는 File/Row Group 단위로 병렬처리가 가능합니다.
만약 하나의 파일이 정말 크다고 가정하면 해당 파일은 여러 개의 row group 이 존재할 것이고 상황에 따라 여러 개의 태스크가 병렬적으로 각 row group을 읽을 수도 있습니다. - 하나의 파일에 대해 여러 Task가 각자 맡은 Row Group 범위에서, 쿼리에 필요한 컬럼에 해당하는 Column Chunk들에 대해 IO 요청을 합니다.
- page 단위로 인코딩/압축 이 진행되니 CPU 레벨에서는 page 단위로 병렬 처리가 됩니다.
Configurations
Configurations을 읽어보면 Parquet의 병렬성을 위한 설정임을 알 수 있습니다.
다만 해당 부분은 현재의 병렬 처리 환경에 따라 고려하여 설정이 필요합니다.
Row Group:
Larger row groups allow for larger column chunks which makes it possible to do larger sequential IO. Larger groups also require more buffering in the write path (or a two pass write). We recommend large row groups (512MB - 1GB). Since an entire row group might need to be read, we want it to completely fit on one HDFS block. Therefore, HDFS block sizes should also be set to be larger.
An optimized read setup would be: 1GB row groups, 1GB HDFS block size, 1 HDFS block per HDFS file.
Data Page:
Data pages should be considered indivisible so smaller data pages allow for more fine grained reading (e.g. single row lookup). Larger page sizes incur less space overhead (less page headers) and potentially less parsing overhead (processing headers).
Note: for sequential scans, it is not expected to read a page at a time; this is not the IO chunk.
We recommend 8KB for page sizes.
Parquet Page Compression
snappy 압축 방식을 대부분 채택하고 있습니다.
25년 10월 기준, 데이터브릭스에서는 delta lake의 기본 파일 압축 방식을 zstd로 변경하였습니다.
RLE
ETC
- 파케이에서 지원하는 데이터 타입, 특히 타임스탬프 관련하여서 확인이 필요
- 메타데이터는 Thrift metadata 정의를 포함하며 직렬화를 위해 TCompactProtocol 사용
Ref.
01. [Docs] https://parquet.apache.org/docs/
02. [youtube] https://www.youtube.com/watch?v=1j8SdS7s_NY
'Data Engineering' 카테고리의 다른 글
| Pruning 기법 정리하기 (0) | 2026.02.02 |
|---|